Mode 1: Standard Prompting with Prompting Techniques
Definition
Prompting techniques are structured methods used by actors to craft prompts for an LLM. These techniques can significantly enhance the quality of the LLM’s responses without requiring additional actors. As shown in Figure, the only actors involved in the entire process are 👤 Human and 🤖 LLM. Using different prompting techniques introduces variations in the process, most of which occur before the LLM generates content—in other words, during the planning stage. Given the numerous prompting techniques proposed and the extensive literature review and report already conducted, we only outlined the several key submodels in this subsection, each corresponding to a specific prompting technique.
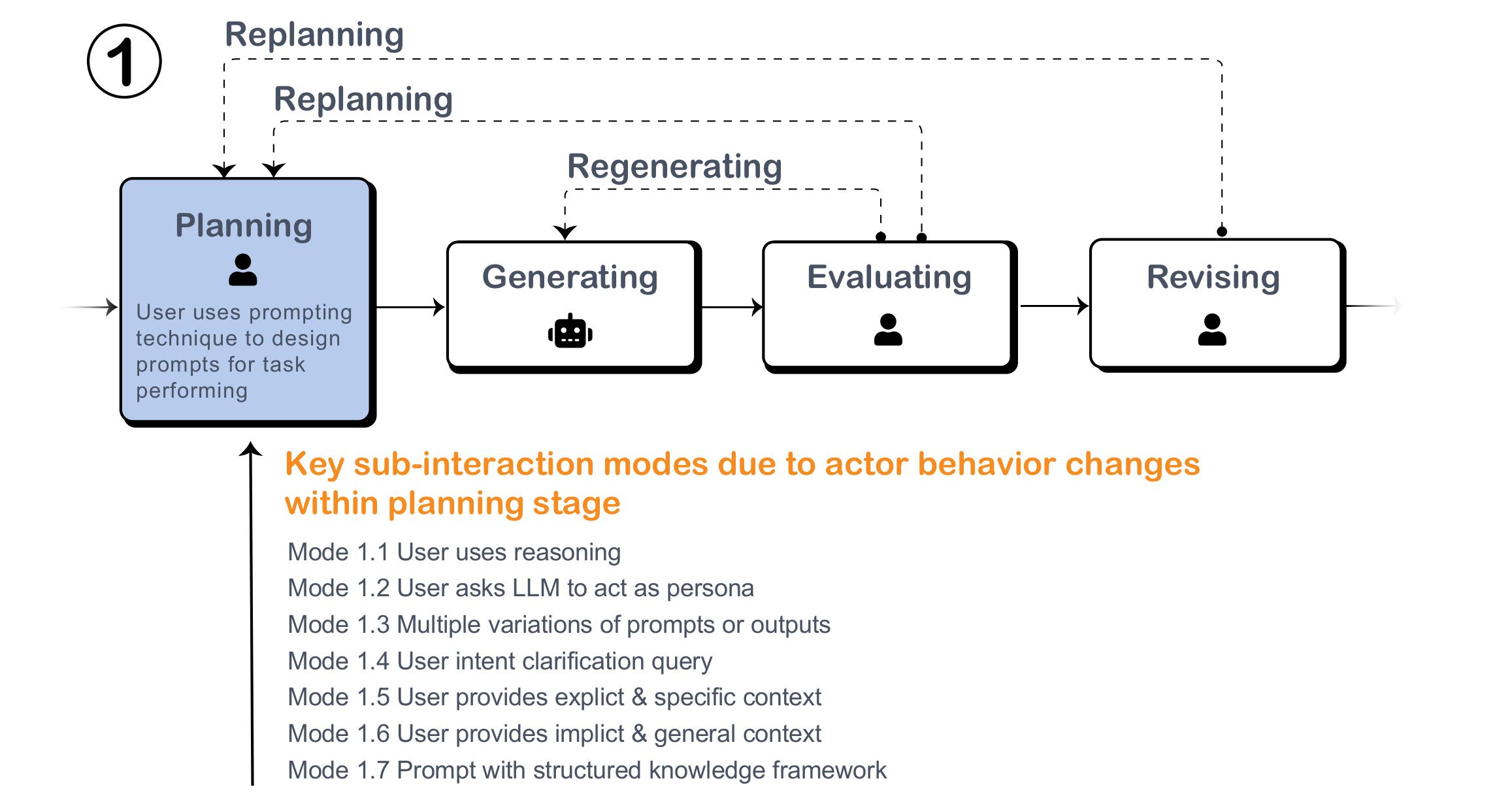
Figure: The Planning Phase integrates various sub-interaction modes, each designed for specific task needs.
Key Sub-Interaction Modes and Examples
Submode 1.1. User/LLM uses reasoning in prompting
This approach breaks down complex tasks into smaller, manageable steps, using outputs from earlier steps to guide subsequent ones through reasoning methods like chain-of-thought. Various forms of reasoning are applied in prompt-based task performing applications. In question answering, generating multiple reasoning chains and integrating relevant intermediate steps leads to more accurate and relevant responses than standard prompting. In code repairing, decomposing a problem’s code into smaller pieces can allow a human user to focus on specific sections for more effective bug fixes.
Submode 1.2. User asks LLM to act as a persona
By assigning LLMs roles similar to humans, they can be utilized for various purposes. For example, an LLM can act as a mindfulness instructor with a sense of humor, providing clear explanations of mindfulness activities and practical advice on how to practice them. It can also serve as an expert teacher for constructive reframing in supportive communication coaching, adopting perspectives such as zero-critique or one-critique approaches. Additionally, an LLM can take on the role of a "devil's advocate," offering challenging opinions to facilitate group discussions.
Submode 1.3. User incorporates knowledge framework in prompting
The user can incorporate a predefined knowledge framework into the prompt, enabling the LLM to generate responses aligned with that framework. For example, integrating a mental health psychology framework allows the LLM to perform thought reframing through avoiding negative thinking traps, reflecting evidence, and emphasizing positivity and empathy. Similarly, in a story-writing task, employing a hierarchical prompting framework—including elements such as characters, plots, and themes—can lead to more enriched storytelling.
Submode 1.4. User is asked for intent clarification by LLM
LLM proactively refines its output by clarifying user intent through iterative questions, such as gradually aligning generated images with the user’s intentions, or providing more accurate responses when retrieving knowledge from a knowledge base by actively asking questions to ensure intent alignment.
Submode 1.5. User/LLM designs multiple prompt variations or LLM generates multiple output variations
The user designs (or asks the LLM to design) multiple variations of a prompt, or the LLM itself generates multiple outputs, such as various sentence rewriting suggestions, qualitative coding suggestions, contrasting with the single input/output approach in standard prompting.
Submode 1.6. User gives LLM explicit task context and specific steps
Context is the external information or additional context that can steer the model to better responses. The user provides explicit instructions and detailed input to the LLM to generate output. For example, in LLM-supported qualitative coding, the user may provide a highly specific codebook outlining possible high-level codes, definitions, and examples, enabling the LLM to identify similar text across a large dataset.
Submode 1.7. User gives LLM implicit context and general requirements
In contrast to submode 1.6, this mode requires the user to provide only a minimal level of context and general requirements as input, leaving the LLM to perform some level of deduction to understand the user’s intent. For example, in an in-vehicle conversation scenario, according to the user’s setup on LLM, the LLM assistant must make assumptions based on limited user utterances and take appropriate actions, such as playing music or adjusting the air conditioning.