Mode 6: LLM for Knowledge Retrieval
Definition
LLMs are well-regarded for their extensive pretraining on vast datasets; however, users often require answers derived from more specialized domain knowledge, such as medicine and clinical base reasoning. In such cases, knowledge retrieval enables LLMs to access external data sources without requiring additional model training. This interaction mode augments standard prompting by introducing another actor—a knowledge base—into the planning phase. A typical example of this is retrieval-augmented generation (RAG), where LLMs analyze the semantic similarity between the user’s prompt and entries in the external knowledge base, the system can identify the most relevant data within the knowledge base. This selected data is then combined with the user’s prompt and sent as a single query to the knowledge base.
During the planning stage, LLMs can interact with external knowledge bases in various ways, introducing flexibility beyond conventional prompting. These variations may involve different methods of querying and incorporating external information sources.
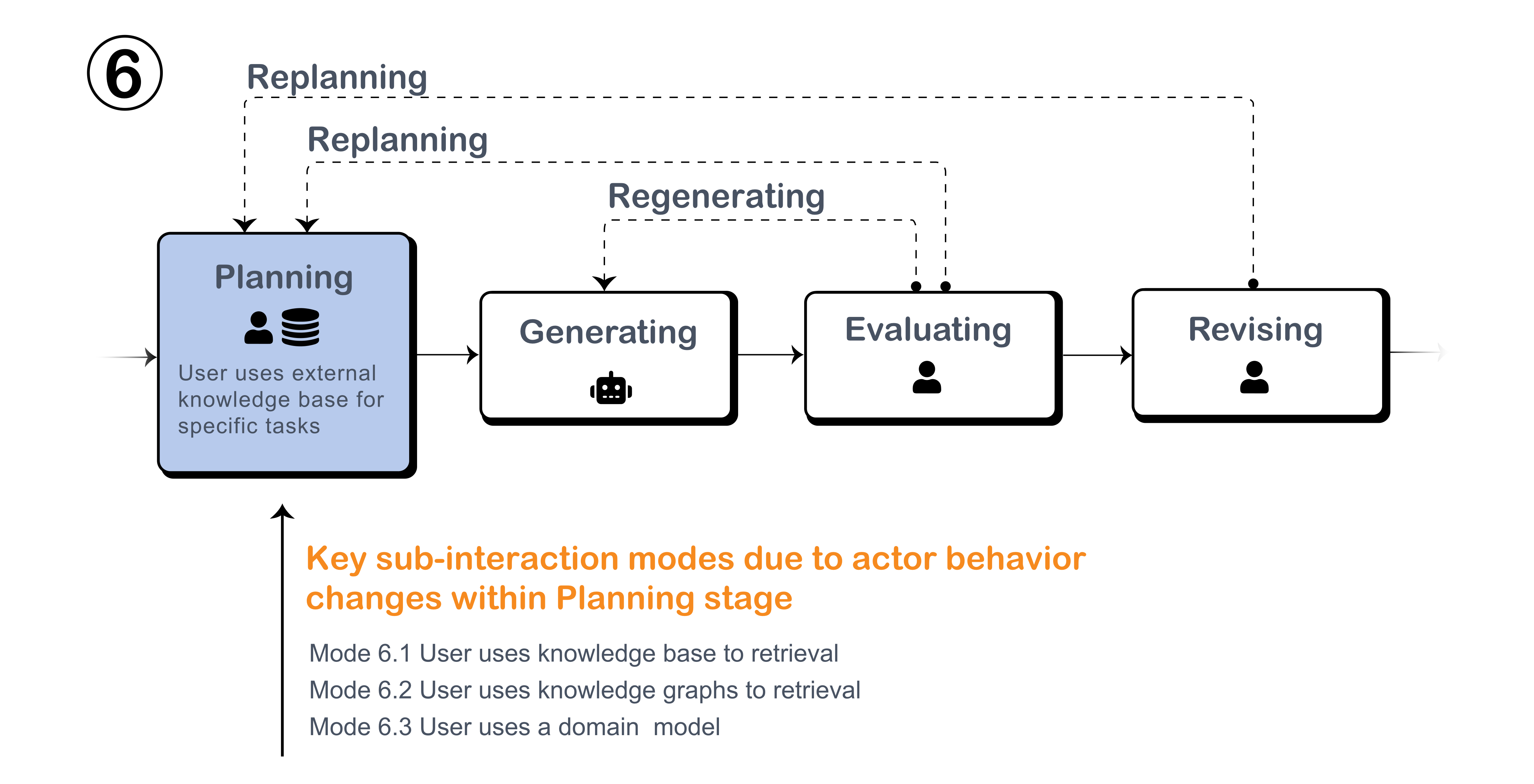
Figure: How knowledge retrieval methods integrate into the Planning stage.
Key Interaction Modes and Examples
User uses prompting techniques to prompt LLM for knowledge base retrieval.
While external knowledge sources can generate a wealth of useful information through additional models, they occasionally fail to produce highly accurate responses. This inaccuracy can stem from an incomplete understanding of the user’s query or from ambiguities within the query itself. Accurately responding to user queries amidst a large volume of information is therefore a non-trivial task.
-
Actively asking intention. Zhang et al. identified the problem of knowledge alignment in knowledge retrieval, which enhances the prompting techniques of LLM. This approach enables LLMs to actively prompt users to clarify their requirements, thereby improving the accuracy of the responses provided.
-
Explicitly reasoning. To enhance LLM’s ability to retrieve information from lengthy texts, Lee et al. proposed novel lookup strategies with their Read Agent system. This approach involves first identifying relevant information from a compressed memory representation, followed by retrieving passages from the original text. This method effectively extends the retrieval context window, allowing LLMs to access and process longer texts.
User provides LLM a graph for knowledge base retrieval.
Exploring vast amounts of information within an external knowledge database can be time-consuming and prone to inaccuracies. To address this, Du et al. proposed the CARE reading assistant for user manual navigation. CARE refines retrieval by locating the most relevant node within a graph, where each node represents a concept from the required knowledge base. By structuring retrieval this way, CARE aims to reduce the user’s reading burden while ensuring high-quality retrieval.
User uses domain model to provide assistance to LLM.
Some domains, such as legal judgment, heavily depend on precedents for making informed decisions. A domain-model that is trained with datasets of expert knowledge can enhance the LLM’s contextual understanding and accuracy in this setting. In the proposed framework from Wu et al., the domain model efficiently identifies relevant precedents, providing candidate labels and contextual information that allow the LLM to make a deeper comprehension decision.