Mode 4: Multi-Model Collaboration
Definition
Often, models can collaborate to accomplish complex tasks that were previously beyond the capabilities of single LLM, or to enhance performance in areas like image or video generation. This augmentation typically occurs during the generation stage, where LLMs generate responses in collaboration with other models. This requires multiple generative models to collaborate, in contrast to those collaboration between LLM and other traditional predication models.
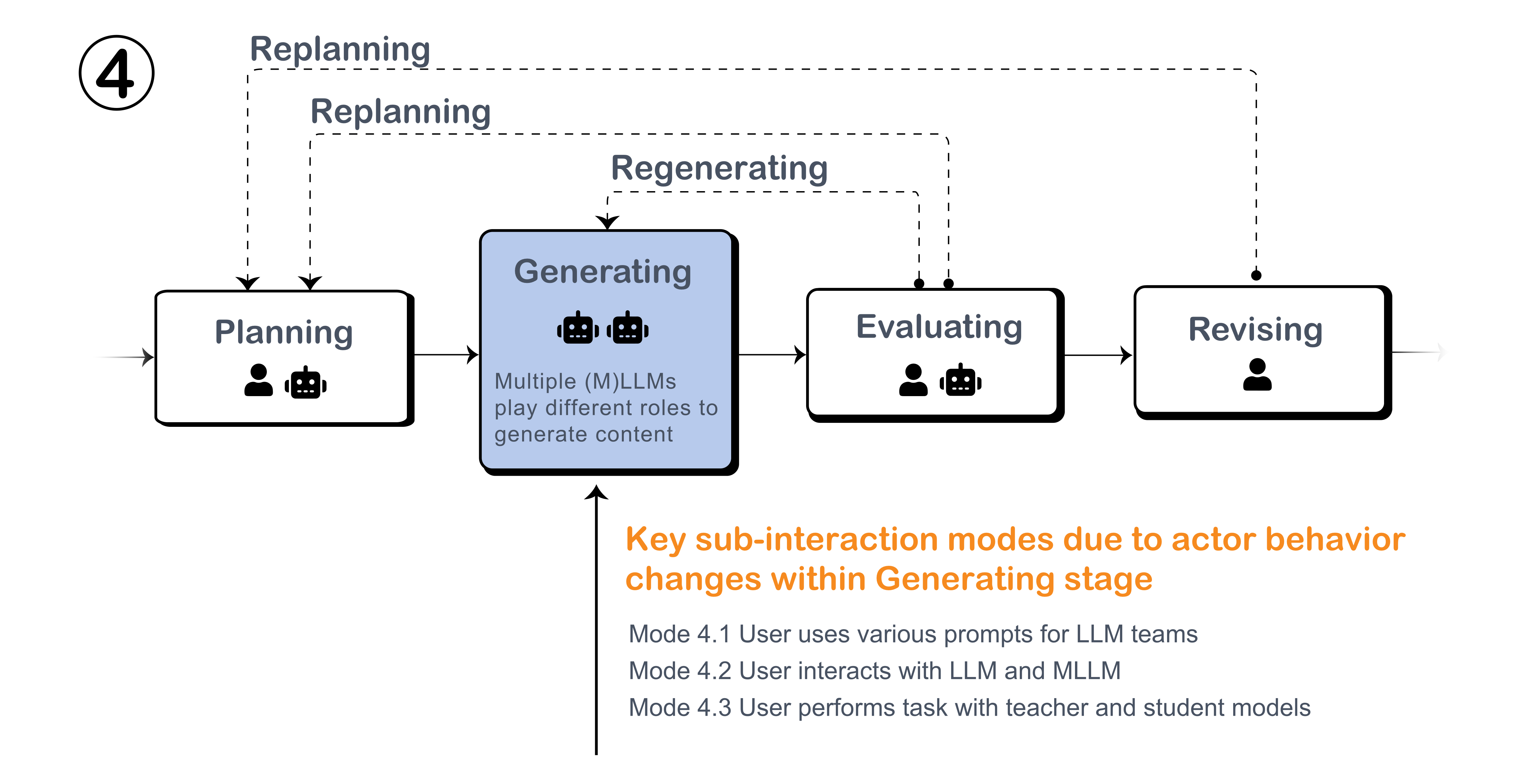
Figure: Key modes during the Generating Stage in multi-model collaboration.
Key Interaction Modes and Examples
Multiple LLMs collaborate with prompting techniques.
- Role-play. Tang et al. proposed MedAgents, a framework that enables LLM-based agents to engage in role-playing scenarios to collaboratively address problems through multi-round discussions. The multi-agent team can also perform users’ given task by having an agent as planner, and others as different task performers like researchers, story planners, writers, etc. with LLMs themselves as evaluators during the process to evaluate the results. It can also perform team collaboration with each other like a social community.
Collaboration between LLM and MLMM.
This is a typical mode in which an LLM can perform tasks across multiple modalities, such as processing images and videos. For instance, Multi-modal LLMs (MLMMs) can accept images as input, collaborating with vision models to generate labels for images or generate images based on LLM-refined prompts, through generating multiple variations and prompt correction. Additionally, tools like DesignAID utilize diverse semantic embeddings to broaden the creative scope of generated designs, expanding visual possibilities without fixation on a single idea. The collaboration of LLMs and vision-language models (VLMs) enhances multimodal language generation by improving both linguistic fluency and visual conditioning, allowing the LLM to generate linguistically coherent responses while retaining relevant visual cues. Such collaborative frameworks in multi-modal AI have been demonstrated in systems that synthesize complex 3D objects through text prompt, and simulate autonomous driving scenes that direct 3D scene edits, integrating assets into realistic simulations.
Multiple LLMs collaborate with UI.
This mode allows users greater flexibility in configuring models, including their functions, purposes, and prompts, facilitated through different user interfaces. For example, EvalLLM enables two LLMs to collaborate, with one acting as a generator and the other as an evaluator, to enhance task generation and response assessment for the primary generator model. The user interface enables more refined configuration of prompt inputs and displays evaluation results more effectively. Additionally, this kind of collaboration between multiple models can be done through the user interface. For instance, one model might serve as the content generator, while other functions as an evaluator model. This interface allows users to input prompts for both the planning and evaluation stages, facilitating the development of evaluation criteria. Users can modulate the emotional expressions of an LLM-powered chatbot integrated with a 3D facial animation model through an interactive interface.
Collaboration between teacher model and student model.
A new interaction model for multi-model collaboration is the "teacher-student" framework, exemplified by the GKT framework. In this setup, a remote LLM (teacher) collaborates with a local, smaller language model (student), often deployed on light-weight mobile devices. When multiple users work simultaneously, the teacher model generates guidance prompts rather than direct responses. The student models receive these guidance prompts, completes the responses, and delivers them to the users. This mode can help reduce the workload of remote LLMs over the long term.